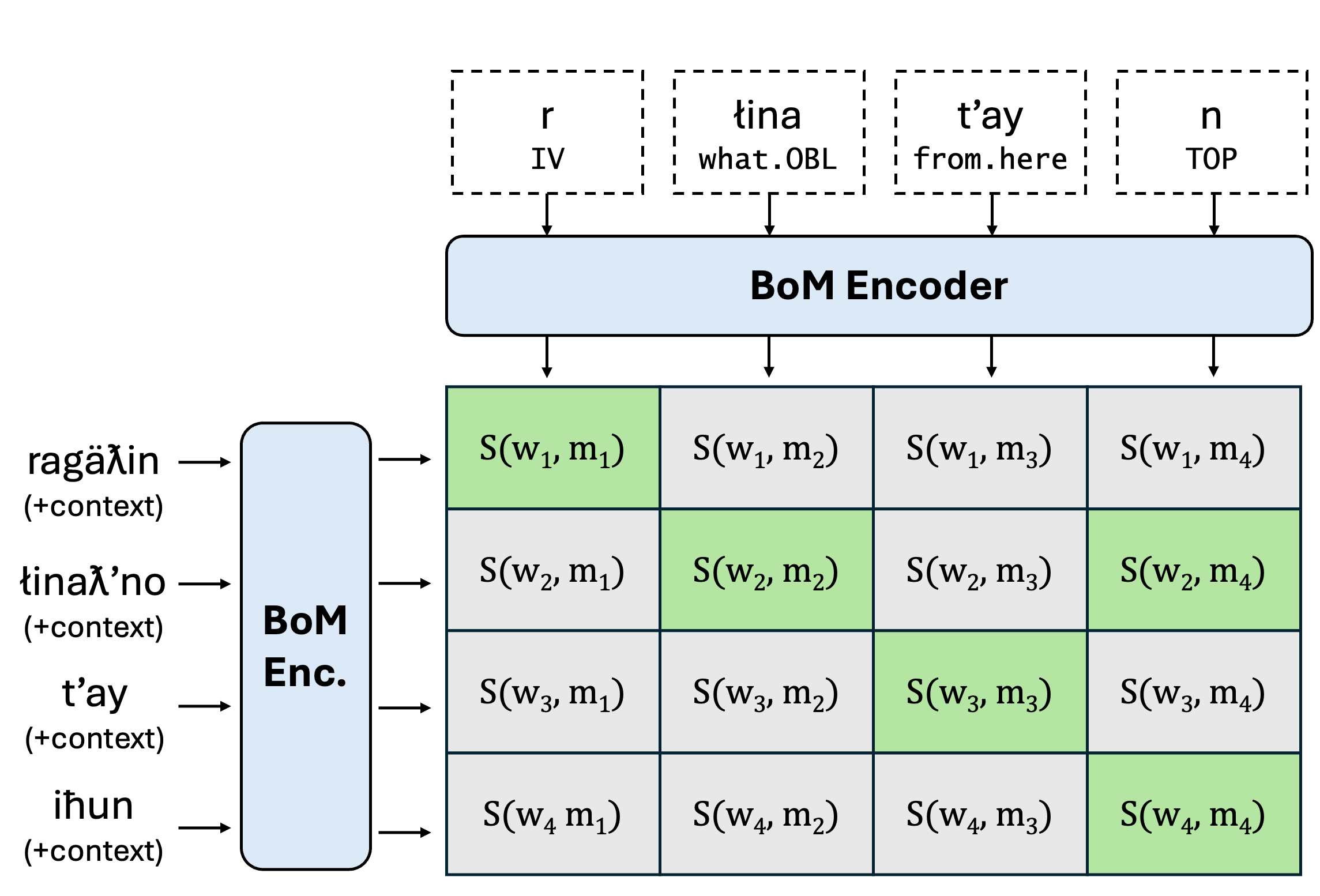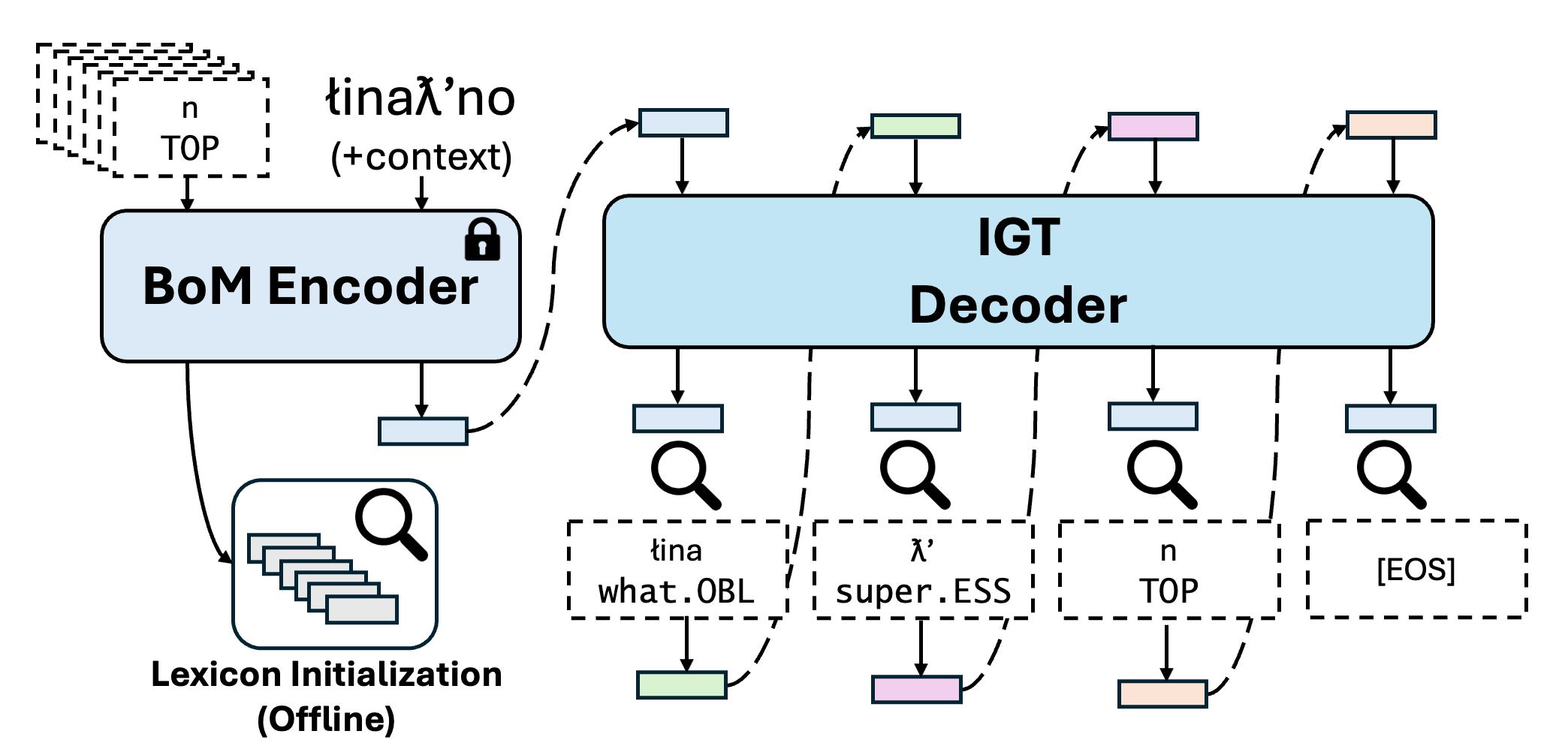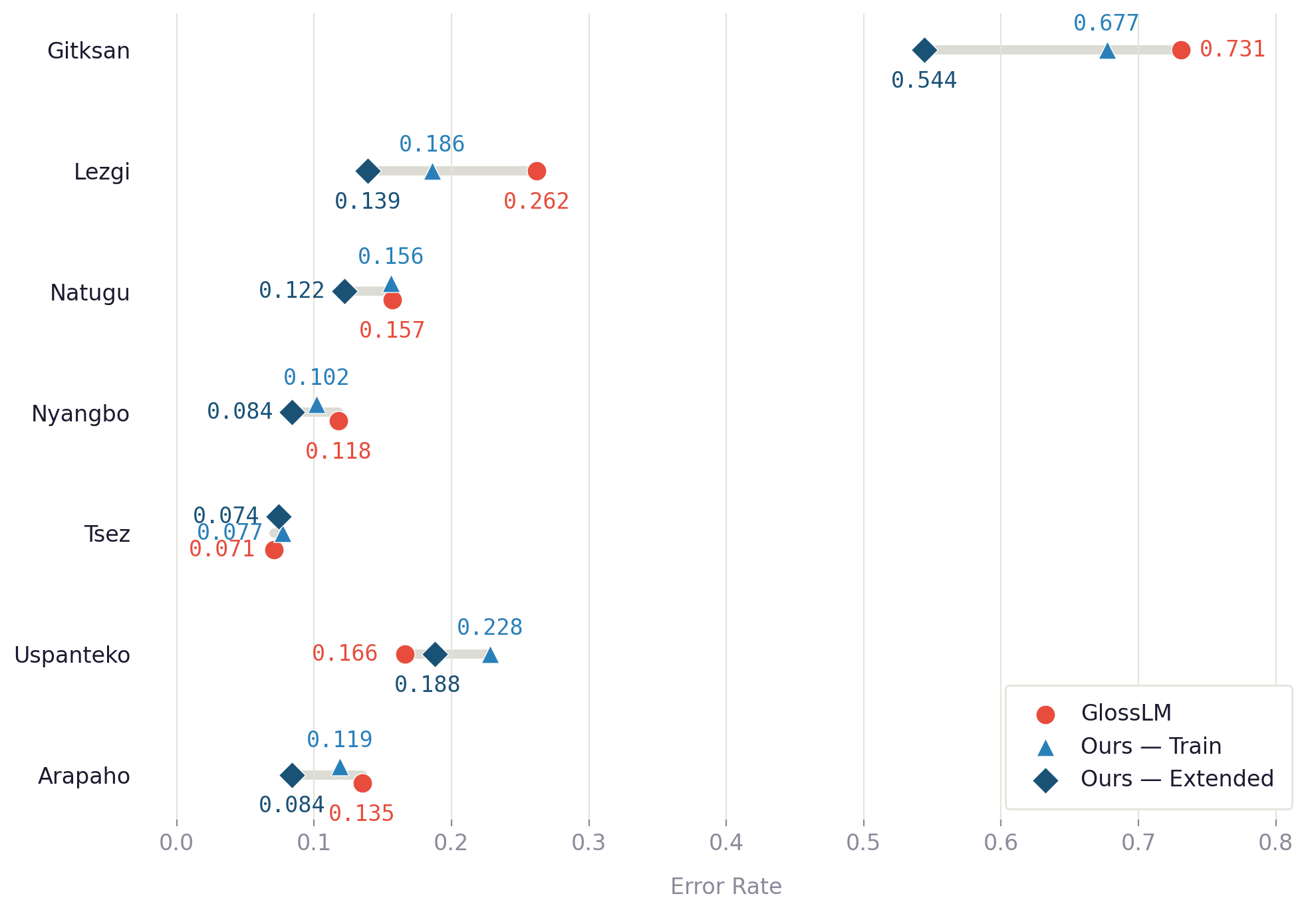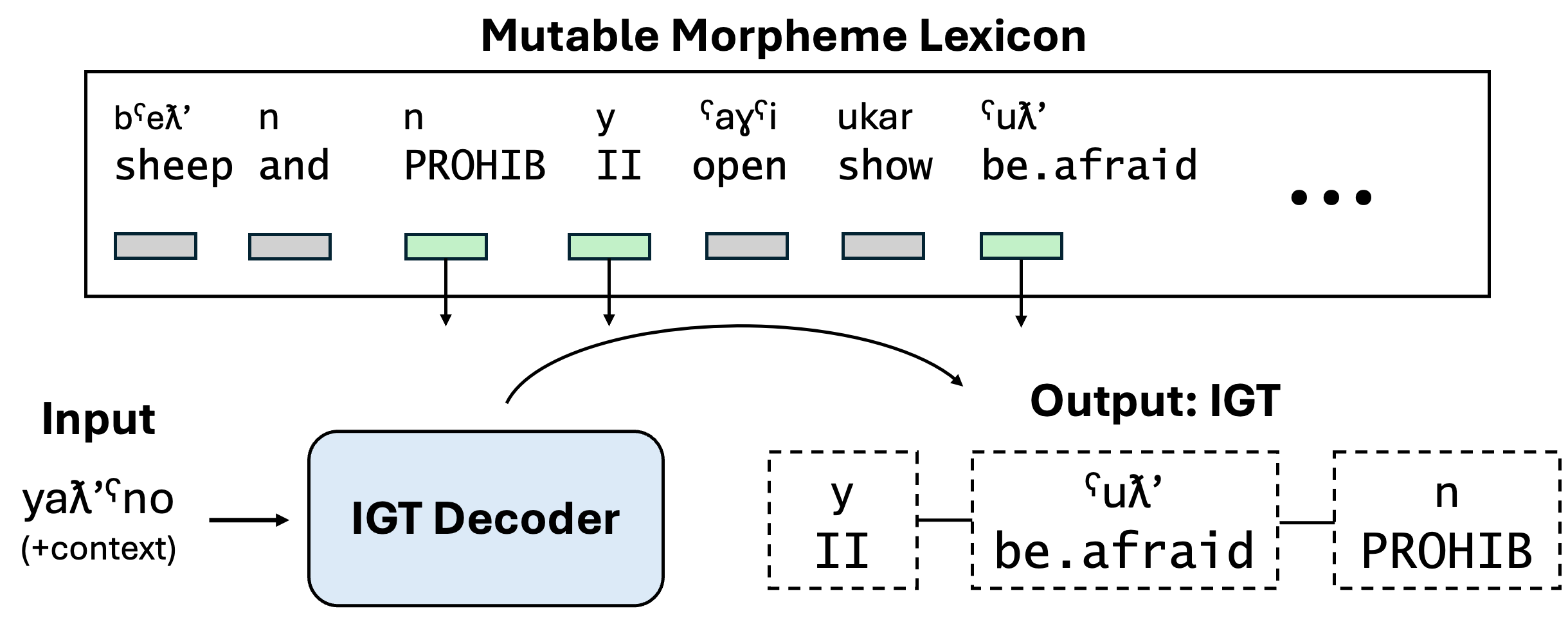
TL;DR: We propose CWoMP, which treats morphemes as atomic form-meaning units with learned representations, enabling interpretable and efficient interlinear glossing that users can improve at inference time by expanding a lexicon — without retraining.